Training data
Storage conditions
In nevisDetect, several detection technologies can be deployed. In general, not all detection technologies can provide a plug-in risk score for every HTTP request. Consider the following example:
BehavioSec and nevisAdapt are deployed for a JSP web application. To be able to compute its plug-in risk scores, BehavioSec needs the keystroke and mouse movement information passed as a HTML form parameter, see chapter Plug-in BehavioSec for details. This means that BehavioSec delivers plug-in risk scores only for HTTP POST requests. nevisAdapt just requires the HTTP headers of the request for the computation of the plug-in risk scores. So for some HTTP requests, both BehavioSec and nevisAdapt provide plug-in risk scores, whereas for other HTTP requests, the plug-in risk scores come only from nevisAdapt. Now suppose that you want to train a normalization model based on BehavioSec and nevisAdapt plug-in risk scores. The training data for this normalization model consist of HTTP requests with plug-in risk scores from both BehavioSec and nevisAdapt. There is no need to store plug-in risk scores of HTTP requests that you cannot use for the training of our normalization model. This can be configured with the so-called storage condition.
For every plug-in risk score a storage condition can be defined. A storage condition consists of a numeric confidence threshold and a qualifier regarding the presence of the plug-in risk score. The following values for the qualifier are defined:
- IGNORE means that the plug-in risk score will never be stored.
- REQUIRED means that the presence of the plug-in risk score is required. If the plug-in risk score is not present, no plug-in risk scores at all will be stored.
- OPTIONAL means that the plug-in risk score is optional. It will be stored if present. Storing any other plug-in risk score is not influenced.
In case of the above example, the value of the qualifier should be REQUIRED; this setting will only store plug-in risk scores of HTTP requests with both BehavioSec and nevisAdapt plug-in risk scores. Another possibility is to use rule-based normalization. For more information, see Rule-based models.
If it is not clear which plug-in risk scores to use for the normalization models for all plug-in risk scores, configure the qualifier OPTIONAL. But note that the configuration of the storage conditions influences the required storage space.
We will come back to the confidence threshold after the explanation of a training data set.
Training data set
You configure a training data set by selecting some plug-in risk scores and by setting a time frame. The number of the selected plug-in risk scores defines the dimension of the training data set, whereas the time frame defines the size. Due to computational reasons the number of training data must be limited.
The user can configure several training data sets without influencing the storage space. The sets are referenced by the normalization model by their unique name, which is given to them by the user.
Confidence threshold
The confidence threshold configuration attribute of a storage condition is of relevance in two situations:
- If the confidence of the plug-in risk score is below the threshold, the risk score will not be stored. Thus, the risk score will never be part of any training data set.
- For the computation of the normalized risk score, nevisDetect checks that all plug-in risk scores are above the confidence threshold of the related storage condition. This is to make sure that the plug-in risk scores used for computing the normalized risk score are from the same population as the training data used for training the normalization model.
The confidence threshold is a means to influence the false-positive rate. A false-positive HTTP request is a legitimate request detected as fraudulent, whereas a false-negative request is a fraudulent request falsely considered as legitimate by the system. The higher the confidence threshold, the more false-negative requests might slip through the detection process. See the figure below:
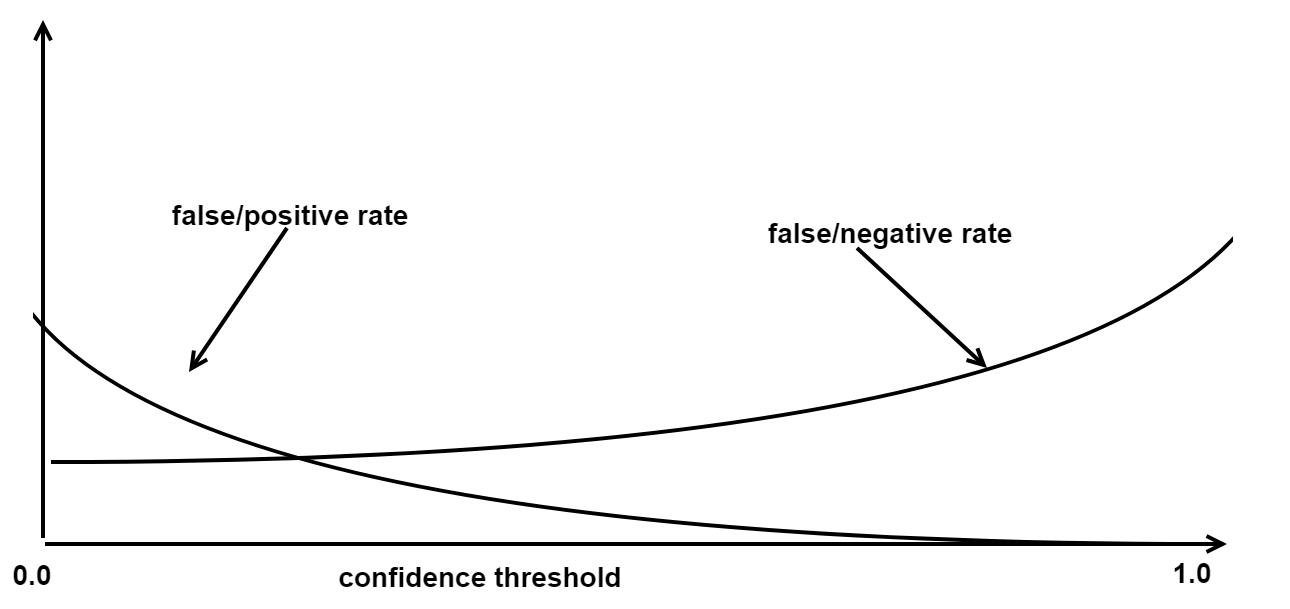
The chosen value of the confidence threshold always represents a trade-off between security and user convenience. A low confidence threshold increases the security but lowers the user convenience, whereas a high confidence threshold increases the user convenience but decreases security.